In modern software development, the speed of delivery is matched only by the demand for quality. Yet, countless engineering hours are lost to a common, persistent bottleneck: mismanaged test environments. Issues like configuration drift, data inconsistencies, and manual handoffs create friction, delay releases, and allow critical bugs to slip into production. The difference between a high-performing team and a struggling one often lies in their approach to testing infrastructure. A robust strategy for test environment management is no longer a luxury; it is a fundamental component of a successful delivery pipeline.
This guide moves beyond theory to provide a definitive roundup of actionable test environment management best practices. We will explore 8 critical strategies that you can implement today to build a more resilient, efficient, and reliable workflow. You will learn how to:
- Achieve perfect environment parity and eliminate configuration drift.
- Automate provisioning and teardown to save time and reduce costs.
- Master test data management for consistent, reliable testing outcomes.
- Implement proactive monitoring to catch issues before they impact your team.
- Streamline handoffs between development, QA, and release teams.
By mastering these practices, you can eliminate rework, accelerate feedback loops, and empower your teams to ship with confidence. This listicle is designed for software teams, DevOps engineers, and QA professionals who need practical, specific steps to transform their testing infrastructure from a source of frustration into a strategic asset. Let's dive into the core practices that will stabilize your environments and supercharge your release velocity.
1. Environment Parity and Configuration Management
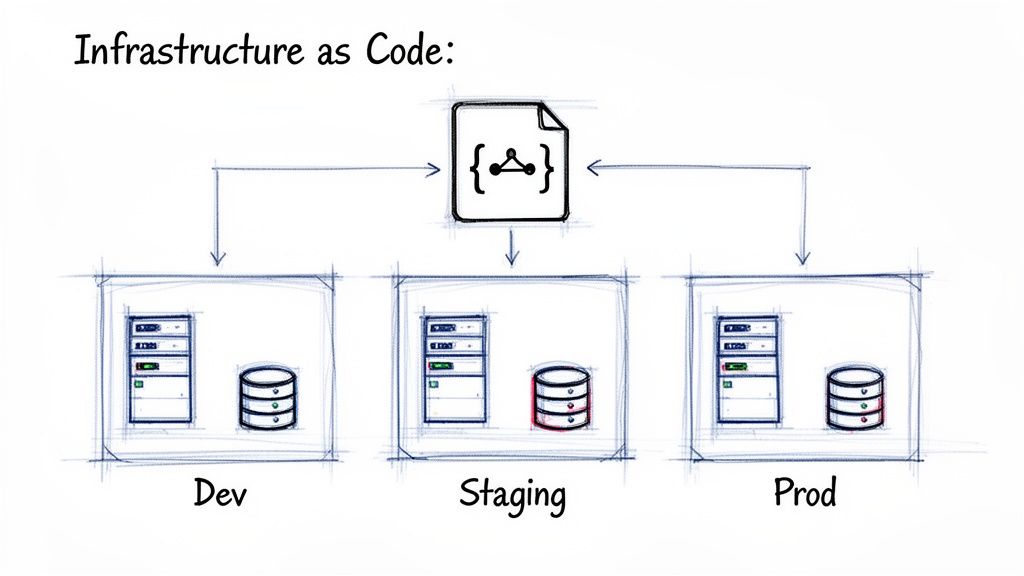
The infamous "it works on my machine" problem is a classic source of friction between development and operations teams. This issue almost always stems from a lack of environment parity: subtle (or significant) differences between development, staging, and production environments. Achieving parity means ensuring that every environment, from a local developer laptop to the final production server, is as identical as possible. This consistency is a cornerstone of effective test environment management best practices.
It covers everything from operating system versions and patch levels to installed libraries, application dependencies, network configurations, and third-party service endpoints. By standardizing these elements, you create a predictable and reliable pipeline where a test passed in a lower environment provides a high degree of confidence that the code will behave exactly the same in production. This minimizes deployment-day surprises, reduces bug resolution cycles, and accelerates the entire software delivery lifecycle.
Why It's a Top Priority
Maintaining environment parity is crucial because it validates the integrity of your entire testing process. Without it, you are not truly testing how your application will perform live. A test that passes in a staging environment with a different database version or API dependency than production is, at best, an approximation. At worst, it provides a false sense of security, allowing critical bugs to slip through unnoticed.
Cloud-native leaders have championed this practice for years. For instance, Spotify uses Infrastructure as Code (IaC) to programmatically define and provision identical staging and production setups, while Amazon leverages AWS CloudFormation templates to spin up consistent, on-demand test environments that mirror their live infrastructure.
Actionable Implementation Tips
Achieving and maintaining parity requires a deliberate, tool-driven strategy. Here’s how to implement it effectively:
- Embrace Containerization: Use Docker to package your application and its dependencies into a single, portable container. Define your environment in a
Dockerfileand share it across all teams to ensure identical runtimes everywhere, from local development with Docker Compose to production clusters managed by Kubernetes. - Implement Infrastructure as Code (IaC): Use tools like Terraform or Ansible to define your infrastructure (servers, load balancers, databases) in version-controlled configuration files. This makes provisioning a new, identical environment a repeatable command like
terraform apply. - Version Control All Configurations: Store all environment configuration files—not just application code—in a Git repository. This includes Dockerfiles, Terraform scripts, and application settings. Use a pull request workflow for all changes to ensure peer review and a complete audit trail.
- Automate Environment Audits: Write scripts to periodically check for "configuration drift." For example, create a scheduled CI/CD job that uses
aws clioraz clito compare the live state of your cloud resources against your Terraform state file and alert on any discrepancies.
2. Automated Test Environment Provisioning
The days of manually configuring servers and waiting days for a new test environment are over. Modern software delivery demands speed and agility, which is where automated test environment provisioning becomes a non-negotiable practice. This approach involves using code and automation tools to create, configure, and tear down complete, isolated test environments on-demand. By scripting the entire process, teams can eliminate manual effort, drastically reduce human error, and accelerate feedback loops.
This automation is the engine behind modern Continuous Integration/Continuous Delivery (CI/CD) pipelines. Instead of sharing a single, static staging environment that often becomes a bottleneck, developers can spin up a fresh, pristine environment for every feature branch or pull request. This ensures tests are run in a clean, isolated state, free from the interference of other ongoing work, making it a cornerstone of effective test environment management best practices.
Why It's a Top Priority
Automated provisioning directly impacts development velocity and testing reliability. When environments are created manually, they are slow to build, prone to configuration drift, and costly to maintain. Automation transforms them into ephemeral, disposable resources that can be summoned in minutes and destroyed just as quickly, optimizing resource usage and cost. This enables parallel testing at a massive scale, which is impossible with manual methods.
Hyperscalers have perfected this approach. For example, GitHub Actions can automatically spin up ephemeral test environments for each pull request, providing immediate feedback. Similarly, Google Cloud and AWS leverage their native Infrastructure as Code (IaC) tools, Terraform and CloudFormation respectively, to provision complex test infrastructures on-demand for thousands of concurrent test runs. Learn more about the core principles of automating complex workflows to see how this fits into a broader strategy.
Actionable Implementation Tips
Adopting automated provisioning requires a shift to an "everything as code" mindset. Here are practical steps to get started:
- Define Infrastructure as Code (IaC): Start by writing Terraform or AWS CloudFormation scripts that define your complete environment, from virtual machines and networks to databases. Commit these scripts to a Git repository alongside your application code to keep them in sync.
- Leverage Containerization: Use Docker and a
docker-compose.ymlfile to define how your application and its dependent services run together. Containers provide lightweight, fast-starting, and isolated runtimes that are perfect for ephemeral test environments. - Integrate with Your CI/CD Pipeline: Create a job in your Jenkins, GitLab CI, or GitHub Actions workflow that runs
terraform applyto build the environment whenever a new pull request is opened. This job should run before the testing stage. - Automate Cleanup: Implement an automated teardown job that runs
terraform destroyafter tests are complete or when a pull request is merged/closed. This crucial step prevents orphaned resources, avoids resource leaks, and minimizes cloud costs. - Secure Your Secrets: Do not hardcode secrets. Use a dedicated secrets management tool like HashiCorp Vault or AWS Secrets Manager. Your CI/CD pipeline should fetch secrets at runtime and inject them into the environment as environment variables.
3. Test Data Management and Isolation
Unreliable test results are often not a code problem but a data problem. When tests interfere with each other by modifying the same dataset, or when test data is inconsistent, the entire testing process becomes fragile and untrustworthy. Test data management and isolation is the practice of creating stable, repeatable, and isolated datasets for testing activities. It ensures that each test run starts from a known state and does not impact other concurrent tests, which is a cornerstone of reliable automated testing.
This discipline involves generating predictable datasets, masking sensitive information to comply with regulations like GDPR and HIPAA, and resetting the environment's state after each test. Proper test data management prevents data contamination, ensures tests are deterministic, and allows for parallel execution without conflict. It is fundamental to building a robust and scalable CI/CD pipeline and is a critical component of any mature test environment management best practices strategy.
Why It's a Top Priority
Effective test data management is crucial because it directly impacts the reliability and validity of your test outcomes. Without it, you face flaky tests that fail intermittently for no clear reason, leading to wasted engineering time and a loss of confidence in your test suite. A test that passes only because it ran before another test that corrupted its data provides a false positive, while a failure caused by bad data creates a false negative, masking the real quality of the code.
Leading technology and financial companies treat test data as a first-class citizen. For example, Stripe generates synthetic data that mimics real-world payment patterns, allowing them to test complex transaction scenarios without ever touching real customer information. Similarly, major financial institutions use sophisticated data masking and subsetting tools to create realistic, anonymized datasets for performance testing, ensuring they meet strict PCI compliance standards.
Actionable Implementation Tips
Implementing a robust data strategy requires a combination of tooling and defined processes. Here’s how to do it effectively:
- Generate Data Programmatically: Instead of relying on static seed files, use libraries like Faker (for many languages) or built-in test data factories in frameworks like Ruby on Rails or Laravel to generate fresh, realistic data for each test run. This makes tests self-contained and easy to understand.
- Leverage Database Snapshots: For integration tests, use tools like TestContainers to spin up an ephemeral database in a Docker container for each test suite. Before each test, restore a known-good database snapshot to ensure a perfectly clean slate every time.
- Isolate Test Database Instances: Never share a test database. As part of your automated environment provisioning, include a script that creates a dedicated database instance for that specific test run. The database credentials should be dynamically generated and passed to the application.
- Mask and Anonymize PII: When using production-like data, use tools like Tonic or Spherity to systematically find and replace personally identifiable information (PII) before loading it into a non-production environment. This is non-negotiable for complying with data privacy laws.
4. Environment Monitoring and Health Checks
A test environment is only useful when it is stable, available, and performing as expected. Intermittent failures, slow response times, or unexpected downtime can derail testing schedules, create false negatives, and erode trust in the QA process. Continuous monitoring and automated health checks are essential test environment management best practices that transform environment stewardship from a reactive, fire-fighting exercise into a proactive, preventative discipline.
This practice involves actively tracking the state of your test environments by collecting and analyzing a wide range of metrics. It covers everything from infrastructure health (CPU, memory, disk space) to application performance (response times, error rates) and the availability of critical dependencies like databases and third-party APIs. By establishing a baseline for normal behavior, you can automatically detect anomalies, diagnose root causes faster, and resolve issues before they block entire teams.
Why It's a Top Priority
Proactive monitoring is critical because it prevents test flakiness and saves countless hours of debugging. When a test fails, the first question should be "Is it the code or the environment?" without solid monitoring, teams waste valuable time investigating environmental issues disguised as application bugs. A healthy environment ensures that test results are reliable, which is the entire purpose of the testing phase.
Industry leaders treat their test environments with the same operational rigor as production. Netflix, for example, employs sophisticated health checks to detect service degradation in its complex microservices architecture, ensuring test environments accurately reflect production behavior. Similarly, Slack provides internal status dashboards for all service dependencies, allowing engineers to immediately verify environment health before starting a test run.
Actionable Implementation Tips
Implementing a robust monitoring strategy requires a combination of the right tools and a clear plan. Here’s how to get started:
- Implement Application Health Check Endpoints: In each service, create a dedicated API endpoint like
/healththat checks its internal state and dependencies (e.g., database connectivity) and returns a simple200 OKor503 Service Unavailable. Your CI/CD pipeline should poll this endpoint before running tests. - Combine Infrastructure and Application Metrics: Use a monitoring tool like Datadog, New Relic, or an open-source stack like Prometheus and Grafana to create a dashboard. This dashboard should display both system metrics (CPU, RAM) and key application metrics (HTTP 5xx error rates, API latency) in one place.
- Set Up Meaningful, Actionable Alerts: Configure alerts to notify your team's Slack or PagerDuty channel when a critical metric breaches a threshold (e.g., CPU utilization > 90% for 5 minutes). Ensure alerts include context and a link to the dashboard to speed up troubleshooting.
- Monitor Third-Party Dependencies: Your application's health depends on external services. Use synthetic monitoring tools like Checkly or Uptrends to continuously ping the health endpoints of critical third-party APIs your test environment relies on.
- Automate Common Remediation Tasks: Write simple scripts that can be triggered automatically by alerts to perform basic remediation. For example, if a "disk full" alert fires, a script can automatically run to clear old log files or temp directories.
5. Clear Definition of Ready and Definition of Done for Environments
A common source of wasted cycles and team frustration is starting tests in an environment that isn't fully prepared or, conversely, promoting code before it has been thoroughly validated. To prevent this, leading teams borrow concepts from Agile methodologies, establishing a clear Definition of Ready (DoR) and Definition of Done (DoD) specifically for test environments. This practice introduces formal, agreed-upon quality gates that ensure an environment is stable and configured correctly before testing begins and that all test activities are completed before the code moves to the next stage.
The DoR acts as a pre-flight checklist, preventing QA from encountering avoidable setup issues, while the DoD serves as an exit checklist, guaranteeing that no validation steps were missed. This structured approach creates a predictable, transparent workflow, reduces the feedback loop for environment-related bugs, and builds confidence in the testing process. It is a fundamental component of mature test environment management best practices that bridges the gap between environment provisioning and test execution.
Why It's a Top Priority
Without explicit DoR/DoD criteria, teams operate on assumptions. Developers might assume the environment is ready when it isn't, and QA might push code forward based on an incomplete test run. This ambiguity leads to failed tests, rework, and schedule delays. Formalizing these entry and exit criteria transforms the handoff process from a vague "it's ready" into a verifiable, data-driven event.
Platform engineering teams at companies like Google Cloud have institutionalized this by implementing automated validation of DoR criteria before a test suite is even allowed to execute. Similarly, Amazon enforces a multi-stage DoD across its dev, staging, and production environments, ensuring code meets stringent quality, performance, and security bars at each step before promotion. This discipline is key to managing complexity at scale.
Actionable Implementation Tips
Implementing DoR and DoD for environments requires collaboration between development, QA, and operations. Here’s how to put it into practice:
- Define Criteria Collaboratively: Host a meeting with Dev, QA, and DevOps to create specific, measurable checklists for DoR and DoD. Store these checklists in a shared Confluence or Notion page so everyone has access.
- Establish a "Ready" Checklist (DoR): Your Definition of Ready checklist should include actionable items: all services return 200 OK from their /health endpoint, the correct application version is deployed (verify via an /info endpoint), and required test data is seeded.
- Establish a "Done" Checklist (DoD): Your Definition of Done checklist should confirm: 100% of automated E2E tests passed, performance test results are within 2% of the baseline, SonarQube security scan passed with zero critical vulnerabilities, and all test results are logged in TestRail.
- Automate Gate Checks: Integrate these checks directly into your CI/CD pipeline. For example, add a script that polls the
/healthendpoints and fails the pipeline if any service is unhealthy (DoR). Add a quality gate that checks the SonarQube API for scan results before allowing a merge to the main branch (DoD). - Visualize Status: Create a status page or a dashboard that displays the DoR/DoD checklist for each active test environment. This provides a clear, real-time signal to the entire team about an environment's readiness for the next stage. For an in-depth guide on structuring these processes, you can learn more about Jira workflow best practices.
6. Automated Environment Teardown and Cost Optimization
Ephemeral, on-demand test environments are a powerful asset, but they can quickly become a significant financial drain if left running indefinitely. Automated environment teardown is the practice of systematically and automatically de-provisioning test environments once they are no longer needed. This discipline is a critical component of modern test environment management best practices, directly combating resource waste and controlling cloud expenditure.
This process involves establishing policies and automation scripts that clean up resources after a test run is complete, a feature branch is merged, or a predefined time-to-live (TTL) expires. By implementing automated cleanup, you prevent the accumulation of "zombie" environments that consume valuable compute, storage, and network resources without providing any value. This not only optimizes costs but also ensures a clean slate for future tests, preventing configuration drift and issues caused by lingering, stale environments.
Why It's a Top Priority
In the pay-as-you-go cloud model, every idle resource translates directly to unnecessary spending. Without automated teardown, cloud bills can spiral out of control, and teams may become hesitant to spin up new environments for fear of the associated cost. This creates a bottleneck that stifles innovation and slows down testing cycles. Effective cost optimization ensures that engineering teams can leverage the full power of dynamic environments without financial repercussions.
This practice is standard at hyperscale companies where infrastructure costs are a primary concern. For example, Uber implements aggressive automated cleanup policies to manage its vast microservices testing infrastructure, minimizing cloud waste. Similarly, AWS itself promotes the use of lifecycle policies and tags to automatically terminate or stop test instances after a set duration, a best practice adopted by countless organizations on its platform.
Actionable Implementation Tips
A proactive approach to cleanup and cost control is essential. Here’s how to put it into practice:
- Implement Time-Based Expiration Tags: When provisioning resources with Terraform or CloudFormation, automatically apply a tag like
destroy-after: 2024-10-28T18:00:00Z. Then, run a scheduled nightly script (e.g., a Lambda function) that scans for resources with this tag and de-provisions any that have passed their expiration date. - Integrate Cleanup into CI/CD Pipelines: In your CI/CD tool, configure a job that triggers on pull request
mergeorcloseevents. This job's sole purpose is to execute theterraform destroycommand for the associated environment, ensuring no resources are left behind. - Set Up Budget Alerts and Quotas: Go to your cloud provider's billing console (AWS Cost Explorer or Azure Cost Management) and create a budget for your testing environments. Configure an alert to send a notification to a Slack channel when spending reaches 80% of the budget.
- Leverage Spot Instances: For non-critical, interruptible workloads like performance or load testing, modify your IaC scripts to use cloud providers' spot instances instead of on-demand ones. This can reduce compute costs by up to 90%.
7. Environment Versioning and Configuration Control
Just as application code evolves, so do the environments that host it. Treating environment configurations as an afterthought is a recipe for untraceable errors and painful rollbacks. The solution is to apply the same rigor to your infrastructure as you do to your source code. Environment versioning means managing all configuration files under a strict version control system, like Git, creating an immutable, auditable history of every change.
This practice transforms your infrastructure from a fragile, manually-configured entity into a predictable and reproducible asset. It allows teams to pinpoint exactly when a change was made, who made it, and why. By versioning configurations, you can easily compare differences between environments, roll back to a previously known good state, and coordinate complex infrastructure changes across multiple teams with confidence. This approach is fundamental to modern test environment management best practices, providing the accountability needed to maintain stable and reliable systems.
Why It's a Top Priority
Without version control, your environment's state is ephemeral and undocumented. A manual change made to fix a "quick issue" can introduce subtle regressions that are nearly impossible to debug later. Versioning your environment configurations provides a single source of truth and an explicit audit trail. This transparency is crucial for security, compliance, and operational stability, as it ensures that every modification is deliberate, reviewed, and documented.
This principle is a core tenet of the Infrastructure as Code (IaC) movement. For instance, GitHub manages its own vast infrastructure by storing all environment definitions in Git repositories, enabling a full version history and peer-reviewed change process. Similarly, teams at Shopify and Slack version-control their Kubernetes manifests alongside application code, ensuring infrastructure and application deployments are always synchronized.
Actionable Implementation Tips
Adopting a version-controlled approach to environment management requires a combination of tools and disciplined processes. Here’s how to get started:
- Centralize Configurations in Git: Create a dedicated Git repository for all infrastructure code, including Terraform scripts, Ansible playbooks, and Kubernetes manifests. This repository becomes your infrastructure's single source of truth.
- Embrace Infrastructure as Code (IaC): Use tools like Terraform, AWS CloudFormation, or Helm to define every component of your environment in code. Avoid manual changes in the cloud console; all modifications must be made through code.
- Enforce Pull Request (PR) Workflows: Configure your Git repository to require pull requests for all changes to the main branch. Mandate that at least one other team member must review and approve the PR before it can be merged. This ensures peer review and prevents unauthorized changes.
- Tag and Align Versions: When you release a new version of your application, also create a corresponding Git tag for your infrastructure configuration (e.g.,
infra-v1.2.0aligns withapp-v1.2.0). This makes it simple to roll back both application and infrastructure together if an issue occurs. - Keep Secrets Separate: Never commit secrets (API keys, passwords) into your Git repository. Use a secrets management tool like HashiCorp Vault or AWS Secrets Manager. Your IaC code should reference these secrets by name, and the CI/CD pipeline will inject the actual values at runtime.
8. Cross-Team Handoff Automation and Notifications
The transition of a software build from a development environment to QA, then to staging, and finally to production is a critical process often plagued by manual errors and communication delays. A manual handoff relies on emails, chat messages, or verbal updates, creating opportunities for missed steps, forgotten artifacts, and idle time as teams wait for notifications. Automated handoff workflows are a core component of modern test environment management best practices that solve this problem directly.
By automating these transitions, you create a structured, repeatable, and transparent process. When a developer marks a feature as "ready for QA," an automation rule can trigger a series of actions: verifying that all prerequisites are met, deploying the build to the QA environment, reassigning the task to the QA team, and sending an instant notification with all relevant context. This eliminates the "over-the-wall" mentality, reduces coordination overhead, and significantly shortens the feedback loop.
Why It's a Top Priority
Automated handoffs are crucial for maintaining momentum in a continuous delivery pipeline. Delays between stages are a common source of waste, directly impacting time-to-market. When a QA engineer has to manually check if a new build is deployed or chase a developer for test notes, valuable testing time is lost. This manual friction compounds in complex workflows involving multiple teams and environments, leading to release bottlenecks.
Leading tech and regulated companies have mastered this to accelerate delivery. Microsoft, for its Azure services, uses highly structured, automated handoff processes to manage deployments across globally distributed teams and complex infrastructure. Similarly, financial services firms integrate automated handoffs with regulatory approval gates, ensuring compliance is built into the workflow, not an afterthought.
Actionable Implementation Tips
Implementing a robust handoff system requires a clear map of your delivery process and the right tools to orchestrate it.
- Map All Environment Transitions: Use a tool like Miro or Lucidchart to visually map every handoff point in your delivery pipeline (e.g., Dev → QA, QA → Staging). For each transition, clearly define the entry and exit criteria.
- Define Required Artifacts: For each handoff, create an explicit checklist of required artifacts. For example, the handoff to QA might require links to unit test results, a code coverage report, and the passing SonarQube scan. Use automation to block transitions if these are missing.
- Use Contextual, Instant Notifications: Configure your workflow automation tool (e.g., Jira Automation, GitHub Actions) to send an immediate alert to a specific Slack or Microsoft Teams channel. The notification should include a direct link to the Jira ticket, the build number, and a summary of what needs to be done.
- Integrate Environment Health Checks: As the very first step in a handoff automation, add a script that calls the
/healthendpoint of the target environment (e.g., the QA environment). If the environment is unhealthy, the automation should fail immediately and notify the operations team, preventing a failed deployment. For a deeper dive into structuring these workflows, you can learn more about Jira workflow automation on harmonizepro.com.
8-Point Test Environment Management Comparison
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Environment Parity and Configuration Management | Medium — requires IaC, containers and discipline | Moderate — infra, tooling (Terraform/Ansible), ops time | Consistent test behavior; fewer "works on my machine" issues | Multi-stage pipelines (dev→staging→prod); onboarding new engineers | Reproducible environments; easier troubleshooting |
| Automated Test Environment Provisioning | High — IaC + CI/CD integration and orchestration | High — compute, IaC expertise, CI runners | Fast, on-demand, isolated test runs; parallelization | Per-PR testing, large test suites, CI-driven workflows | Eliminates manual setup; speeds feedback loops |
| Test Data Management and Isolation | High — data masking, seeding, lifecycle automation | Moderate–High — DB tooling, storage, compliance controls | Repeatable, isolated tests; reduced flakiness and data leaks | E2E/regression tests; systems with sensitive data (PII/PCI) | Ensures data privacy; improves test reliability |
| Environment Monitoring and Health Checks | Medium — dashboarding, alerts and log aggregation | Moderate — monitoring platforms, metric storage | Early detection of drift/issues; reduced false negatives | Long-lived test envs; performance-sensitive applications | Proactive issue detection; faster MTTR |
| Clear Definition of Ready and Definition of Done | Low–Medium — process design + automatable checks | Low — documentation, lightweight automation | Fewer premature tests; consistent environment promotions | Teams practicing CI/CD or regulated releases | Clear criteria for handoffs; reduced rework |
| Automated Environment Teardown and Cost Optimization | Medium — lifecycle policies + automation | Low–Moderate — cost tooling, scheduling automation | Lower cloud costs; reduced resource sprawl and drift | Ephemeral environments; large-scale/parallel testing | Cost savings; improved security and resource hygiene |
| Environment Versioning and Configuration Control | Medium — Git workflows + IaC validation | Moderate — VCS, IaC tools, review processes | Auditable configs; ability to roll back and reproduce states | Regulated environments; disaster recovery planning | Full audit trail; reproducibility and safer changes |
| Cross-Team Handoff Automation and Notifications | Medium–High — workflow design, integrations (Slack/Teams/Jira) | Moderate — workflow engine, integrations, maintenance | Fewer missed steps; faster, auditable handoffs across teams | Complex multi-team deployments; regulated releases | Eliminates manual coordination; improves visibility and compliance |
From Best Practices to Business Impact
Navigating the complexities of modern software development requires more than just skilled engineers and innovative ideas; it demands a robust, reliable, and efficient pipeline from code commit to customer value. As we've explored, the often-overlooked discipline of test environment management is the linchpin that holds this entire process together. Adopting these test environment management best practices is not merely an IT housekeeping task; it's a fundamental strategic shift that directly impacts your organization's velocity, quality, and bottom line.
By moving from chaotic, manual processes to a structured, automated framework, you transform your testing infrastructure from a constant source of friction into a powerful competitive advantage. The journey from bottleneck to accelerator begins with the principles we've detailed: achieving environment parity, automating provisioning and teardown, mastering test data, and implementing rigorous monitoring. These practices collectively dismantle the silos and guesswork that plague so many development cycles.
Synthesizing the Strategy: Your Actionable Takeaways
Mastering this domain is a journey, not a destination. The key is to start small and build momentum. Instead of attempting a complete overhaul overnight, focus on incremental improvements that deliver immediate value and build a foundation for future enhancements.
Here are the most critical takeaways to begin your transformation:
- Automation is Non-Negotiable: The single most impactful change you can make is to automate repetitive tasks. Start with environment provisioning using tools like Terraform or Ansible. Once that’s established, automate health checks, and finally, automate the teardown process to reclaim resources and control costs. Automation is your primary weapon against inconsistency and human error.
- Treat Environments as Code (EaC): The principle of version-controlling your environment configurations, just as you do your application code, is paramount. This practice is the bedrock of achieving true environment parity, ensuring that what you test is an exact replica of what you deploy. It eliminates the "it worked on my machine" class of bugs and drastically reduces release-day surprises.
- Clarity and Communication are Essential: Formalize your processes with clear definitions. A "Definition of Ready" for an environment entering QA and a "Definition of Done" for handoffs create unambiguous quality gates. Integrating automated notifications into your CI/CD pipeline and communication tools like Slack ensures that every stakeholder has real-time visibility, preventing delays caused by miscommunication.
- Data Management is a First-Class Citizen: Ineffective test data management can invalidate your entire testing effort. Prioritize creating a strategy for generating realistic, anonymized, and isolated datasets. This not only improves the accuracy of your tests but also ensures compliance with privacy regulations like GDPR and CCPA, protecting your organization from significant risk.
From Practice to Profit: The Broader Business Impact
Implementing these test environment management best practices creates a ripple effect across the entire organization. Developers spend less time fighting fires and more time innovating. QA teams can execute tests with higher confidence and speed. Release managers can orchestrate deployments with predictable, repeatable outcomes.
Ultimately, this operational excellence translates directly into tangible business value:
- Faster Time-to-Market: A streamlined environment pipeline removes bottlenecks, allowing you to ship features and bug fixes to your customers more quickly.
- Improved Product Quality: Consistent, reliable test environments lead to more thorough testing, catching bugs earlier in the cycle when they are cheaper and easier to fix.
- Reduced Operational Costs: Automation, especially in environment teardown and resource optimization, directly cuts down on infrastructure spending.
- Enhanced Team Morale: By eliminating frustrating, repetitive manual work and empowering teams with self-service capabilities, you create a more productive and satisfying work environment.
The path forward is clear. Begin by auditing your current processes, identify the most significant pain point, and apply one of the practices discussed. Whether it's version-controlling a single environment's configuration or automating one health check, each step forward builds a more resilient and agile delivery ecosystem.
Ready to turn these best practices into an automated, self-managing system? Harmonize Pro's Nesty for Jira orchestrates your entire environment management workflow directly within Jira, enforcing quality gates and automating handoffs. See how you can build a world-class testing infrastructure by visiting us at Harmonize Pro.