
Connecting Jira to Power BI is more than just ditching manual CSV exports. It's about turning your raw project data into a powerhouse for strategic decision-making. You're moving from simple, static charts to real-time, interactive business intelligence. The goal is to build dashboards that let you visualize everything from sprint health and cycle times to bug resolution rates, all in one place.
Why Jira and Power BI Is A Powerful Combination
Linking these two platforms creates a single source of truth that changes how your organization uses project data. Engineering leads, QA managers, and product owners can finally have data-driven conversations with stakeholders who don't spend their days inside Jira. The immediate, actionable goal is to spot project risks long before they spiral into major problems.
This pairing helps you get ahead of the curve, shifting from reactive fire-fighting to proactive strategy. Instead of digging through a dozen tickets to explain a missed deadline, you can pull up a dashboard that clearly shows a bottleneck in the QA handoff process.
Unlock Strategic Business Insights
The magic happens when you stop exporting spreadsheets and start building dynamic reports. This move allows for much deeper analysis and helps everyone make smarter decisions, faster. To get a feel for what’s possible, it helps to know how Power BI fits into the larger Microsoft Power Platform.
For large organizations trying to scale their project analytics, this integration is a game-changer. Teams that use a dedicated Jira-to-Power BI connector can build unlimited custom datasets using JQL, allowing for truly tailored dashboards for sprint metrics and bug trends. You can check out some of these Jira and Power BI connector capabilities to see what's possible.
The bottom line is this: you’re transforming Jira from a simple task tracker into a robust business intelligence engine. It gives you the visibility needed to fine-tune workflows, boost team performance, and deliver projects with far more predictability.
From Manual Reporting to Automated Dashboards
Think about what you could do with the hours you'd save by not having to manually compile data every week. That's what this automation does—it handles the grunt work, freeing you up for more important strategic thinking.
- Visualize Sprint Health: Get an immediate answer to "Are we on track?" by monitoring burndown charts, scope creep, and story point completion in real-time.
- Analyze Cycle and Lead Times: Pinpoint exactly where work gets bogged down in your development process, from the moment a task is started to when it's finally marked "Done."
- Monitor Bug Resolution Rates: Get a clear picture of how quickly your team crushes critical bugs and measure the overall quality of your releases.
Automating these reports means everyone is always looking at the freshest data. Of course, the quality of your reports depends on the quality of your data. Following the best practices in Jira from the very beginning ensures your Power BI dashboards are both accurate and reliable.
Choosing Your Jira to Power BI Connection Method
So, you want to get your Jira data into Power BI. Good call. But how you build that bridge is the first big decision you'll make, and it's a trade-off between control, convenience, and how much you want to tinker under the hood. The right path really depends on your team’s technical chops, what you need to report on, and frankly, how much time you have to spare.
Let's start with the most hands-on approach: using Jira’s native REST API with Power BI's Web connector. This route gives you ultimate control. If you love writing very specific JQL queries to pull exactly the data you need and nothing more, this is for you. But with great power comes great responsibility. You're on the hook for managing API token authentication and—this is a big one—staying within Jira's rate limits to avoid getting throttled. The Atlassian community forum has some great discussions if you decide to go down this rabbit hole.
At the complete opposite end of the spectrum is the humble CSV export. Need a quick data snapshot for a single presentation tomorrow? This is your answer. It's fast, simple, and gets the job done for one-off tasks. But let's be clear: it's a manual process, it doesn't scale, and it’s completely impractical for any kind of ongoing, automated reporting.
Finding the Right Balance for Your Team
For most engineering and QA teams I've worked with, the sweet spot is a third-party marketplace connector. These tools are purpose-built to do one thing well: connect Jira to Power BI. They handle all the messy stuff—authentication, API pagination, rate limiting—so you don't have to. You get to skip the infrastructure headaches and jump straight into building reports.
This approach is a lifesaver, especially if you don't have a data engineer on standby. It just works, ensuring your data refreshes are consistent and reliable.
To help you figure out where you land, this decision guide lays out the options based on your end goal.
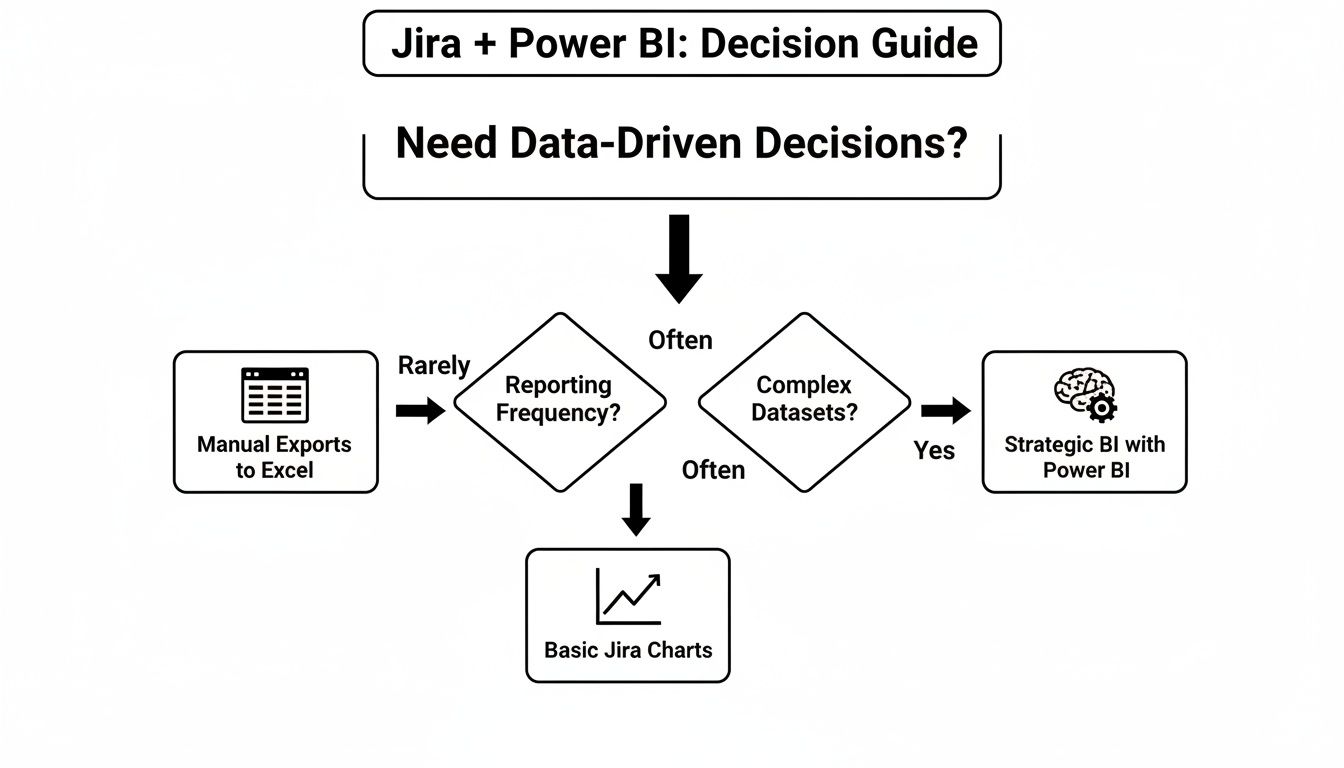
As you can see, if you're aiming for strategic, ongoing business intelligence, you'll want a dedicated connection. For those quick-and-dirty analyses, a manual export might be all you need.
Jira to Power BI Connection Method Comparison
To make the choice even clearer, let's put these methods side-by-side. Seeing the pros and cons laid out can quickly highlight the best fit for your situation.
| Method | Technical Effort | Best For | Key Limitation |
|---|---|---|---|
| Marketplace Connector | Low | Automated, scalable, and reliable dashboards with minimal setup. | Requires a subscription for a third-party application. |
| REST API + Web Connector | High | Full control over data queries and complex, custom integrations. | Requires ongoing management of API tokens and rate limits. |
| CSV Export | Very Low | Quick, one-time data analysis for presentations or simple charts. | Completely manual, not scalable, and prone to human error. |
Ultimately, picking the right connection method is about setting a solid foundation. Once you have a reliable data pipeline in place, you’re ready for the fun part. The next step is to learn how to create a report in Jira that actually tells a story with your metrics.
Crafting Your Dataset with JQL and Custom Fields
The quality of your Power BI dashboards lives and dies by the data you pull from Jira. It's a classic case of "garbage in, garbage out." This is where getting good with Jira Query Language (JQL) becomes your most valuable skill, letting you move past generic data dumps and start building clean, focused datasets.
Think of JQL as a precision filter. Instead of trying to import every single issue from your entire Jira instance—which is a recipe for slow reports and headaches—you can write queries that pull only the data you actually need. This not only makes your reports faster but also keeps your data model much simpler to manage down the line.
Building Smart JQL Queries
A sharp, well-written JQL query is the bedrock of any useful dashboard. It's your first line of defense, making sure only relevant information ever makes it into your analysis.
For instance, a QA manager probably doesn't need to see every story and task. They might only care about bugs from a specific project that were wrapped up in the last sprint. A good JQL query makes that possible.
Here are a few practical examples you can adapt right now:
- Bugs Resolved Last Sprint:
project = "Phoenix" AND issuetype = "Bug" AND status = "Done" AND resolutiondate >= startOfWeek(-1) AND resolutiondate <= endOfWeek() - Stories for an Upcoming Release:
project = "MobileApp" AND issuetype = "Story" AND fixVersion = "Q3 Release" - High-Priority Tech Debt:
project = "BackendServices" AND labels = "tech-debt" AND priority = "High"
Queries like these give you a targeted, manageable dataset that’s so much easier to work with in Power BI. For a deeper look at the logic, the same principles for building filters apply, and this guide on how to create a filter in Jira is a great resource.
Taming Jira Custom Fields
Let's be honest, the real insights are often buried in your custom fields. I’m talking about things like Story Points, Epic Link, or maybe team-specific statuses you’ve configured. Unfortunately, these fields are notorious for causing trouble when you pull them into Power BI. They often show up as nested records or lists, not the clean, simple columns you want.
The secret is to go in expecting this. When you connect to Jira, you should know that you will almost certainly need to spend time in Power Query to "un-nest" or expand those custom field columns to get to the good stuff.
A perfect example is the "Story Points" field. It might import as a record that you have to click into. You’ll need to use Power Query's "Expand Column" feature to pull out the actual number. Another common one is a "Components" field, which might be a list. To analyze work by component, you'll have to expand that list into new rows.
Dealing with these fields isn’t something you do at the end; it’s a core part of building a solid data model from the start. By planning ahead to extract data from these critical fields, you’re ensuring your reports can answer the questions that really matter, like measuring team velocity or tracking progress against epics. This prep work is what turns a messy data dump into a powerful asset.
Shaping Your Data for Performance and Insight
Pulling your Jira data into Power BI is a solid first step, but let's be honest—the raw data is a mess. It's not even close to being report-ready. Think of it as a pile of groceries on your kitchen counter; you can't just serve it up. You have to prep, chop, and combine everything to make something useful. This is exactly where Power Query, Power BI’s data transformation engine, becomes your best friend.
Your first job is to take all that messy, nested data from Jira and flatten it into clean, usable columns. This initial shaping phase is absolutely non-negotiable if you want a data model that performs well and actually makes sense. It’s the foundation for everything else you'll build.
Essential Data Shaping in Power Query
When you first load Jira data, especially from a REST API or a connector, you'll see a lot of columns that just say [Record] or [List]. This is a classic sign of nested data, and it's especially common with custom fields, assignees, components, and other complex fields. The goal here is to expand those records and lists into valuable information.
Start by zeroing in on the most critical columns containing this nested data. The fields column is almost always the main culprit, often hiding dozens of other fields inside of it.
- Expand Nested Records: Find the column header with the double-arrow icon, right-click it, and choose "Expand." Be selective here. Only pick the fields you actually need for your reports, like
summary,issuetype,status, andcreated. Deselecting everything else is one of the most effective performance optimizations you can make. - Split Columns: Sometimes data gets jammed together, like a user's name and their ID. The "Split Column" feature is perfect for breaking these into separate, more useful columns.
- Change Data Types: Power BI does its best to guess data types, but you have to double-check its work. Make sure dates are set to
Date/Time, story points areWhole Number, and any time-tracking fields areDecimal Number. Getting these wrong is a surefire way to run into frustrating DAX errors down the road.
Here's a piece of hard-won advice: remove any columns you don't need for your final report as early as possible in your Power Query steps. Every single extra column bloats your data model, which can kill your refresh times and make your report feel sluggish.
Modeling for Key Jira Metrics
Once your data is clean and tidy, it's time to build the data model. This is where you create relationships between your different queries and start writing DAX (Data Analysis Expressions) measures to calculate the metrics that truly matter to your team.
For instance, you'll likely have one query for your Jira issues and another for your sprint details. By creating a relationship between them (probably on a sprint.id field), you can analyze issue data within the context of specific sprints.
The data model is where you embed your core business logic. Instead of doing one-off calculations inside individual charts, you create centralized DAX measures. This keeps everything consistent and reliable across your entire report.
Here are a few essential DAX formulas to get you started:
- Cycle Time:
Cycle Time = DATEDIFF(Issues[InProgressDate], Issues[DoneDate], DAY) - Lead Time:
Lead Time = DATEDIFF(Issues[CreatedDate], Issues[DoneDate], DAY) - Total Story Points:
Total Story Points = SUM(Issues[StoryPoints])
Creating these as measures, rather than calculated columns, is almost always better for performance. They get calculated on the fly when someone interacts with a visual, keeping the report feeling fast and responsive.
The Impact of Structured Jira Workflows
The cleaner your Jira process is, the easier your Power BI reporting will be. Inconsistent workflows where teams use different statuses or skip critical steps just create a data nightmare. You end up having to build complex, fragile workarounds in Power Query to clean it all up.
This is where tools like Nesty for Jira can be a game-changer. By enforcing structured workflows with features like nested checklists and automated transitions, you guarantee every issue follows a predictable path. You can, for example, build a workflow that automatically captures the precise timestamp when a ticket moves from "In Progress" to "In Review."
That kind of process discipline means the data flowing into Power BI is already clean, consistent, and trustworthy. You'll spend far less time wrestling with data transformations and way more time uncovering actual insights.
Building Dashboards Your Team Will Actually Use
Alright, you've connected Jira, pulled in your data, and shaped it into something useful. Now comes the fun part: building dashboards that your engineering and QA teams will actually want to use. The goal here isn't just to make pretty charts; it's to answer real-world questions and drive meaningful improvements.
A great dashboard tells a story at a glance. A team lead should be able to look at it and immediately spot a bottleneck, understand how a sprint is tracking, or get a handle on quality, all without having to manually sift through Jira tickets. This is where the magic of combining deep Jira data with Power BI's visualization capabilities really happens.
Look at the dashboard above. It's a perfect example of how combining metrics like burndown, cycle time, and handoffs gives a complete picture of project health. It's all about picking the right visuals to tell the right story for the people who need to hear it.
The Sprint Health Dashboard
Every engineering manager lives and breathes by one question: "Is this sprint on track?" A Sprint Health dashboard gives them that answer instantly.
Don't just stop at a basic burndown chart, though. Make it interactive. Overlay a line chart showing the ideal burndown against the actual remaining work. Right next to it, add a stacked bar chart that shows completed story points versus scope creep—any story points that were added after the sprint started. This immediately tells you, "Are we behind schedule because we're slow, or because we keep adding more work?"
- Actionable Question: "Are we going to hit our sprint goal, and what's standing in our way?"
- Key Visuals: A line chart for the burndown, a stacked bar for scope changes, and a few KPI cards for the completion percentage.
- Metrics to Display: Remaining Work (in Story Points or Hours), Completed Work, Added Work (Scope Creep), and Team Velocity.
Cycle Time Analysis for Bottleneck Detection
Cycle time is, without a doubt, one of the most insightful metrics you can track. It measures the total time from when work starts ("In Progress") to when it’s truly finished ("Done"). A solid Cycle Time dashboard is your best tool for finding out exactly where work is getting stuck.
My favorite visual for this is a scatter plot. I plot each completed ticket with its creation date on the X-axis and its cycle time in days on the Y-axis. You can instantly spot the outliers—those tickets that took forever—and see if your cycle time is trending up or down.
Another great option is a simple bar chart showing the average cycle time broken down by issue type or even by assignee. You might discover that bugs take way longer to fix than stories, or that one particular developer is consistently getting overloaded. As you get your hands dirty building these, this practical guide on how to create a Power BI dashboard is a fantastic resource, walking you through everything from connecting data to creating compelling visuals.
QA Handoff and Quality Metrics
The handoff between developers and the QA team is a classic source of friction. A QA Handoff report shines a light on this critical step, measuring how long tickets languish in a "Ready for QA" status before someone actually starts testing them.
For this, I often use a straightforward table or matrix visual. List all the tickets currently waiting for QA and sort them by the longest wait time. You could even add a gauge visual to track the average handoff time against a target, like a 48-hour service-level agreement (SLA). It’s a simple but effective way to encourage everyone to keep work flowing smoothly through the system.
Common Questions About Jira and Power BI
Even with a solid plan, connecting Jira and Power BI can throw some curveballs. Let's walk through a few of the most common snags I've seen teams run into and how to get past them.
These issues pop up all the time, but the fixes are usually pretty straightforward once you know where to look. Nailing these details is the key to building a reporting setup you can actually rely on.
How Do I Handle Jira API Rate Limits in Power BI?
Ah, the dreaded Jira API rate limit. It's there to protect Atlassian's servers, but it can easily torpedo your scheduled data refreshes, especially with large datasets. The classic sign? A timeout error right in the middle of a refresh.
The easiest first step is to schedule your Power BI refreshes during off-peak hours, like overnight. But if you're pulling a lot of data directly from the API, your best bet is to set up incremental refresh in Power BI. This is a game-changer. It tells Power BI to only grab issues that have been created or updated since the last run, slashing the number of API calls you make.
For companies with huge or super-active Jira instances, a dedicated third-party connector is often the sanest path forward. These tools are built from the ground up to manage API calls efficiently, automatically handle rate limits, and use smart backoff logic. It takes all the guesswork out of keeping your data pipeline stable.
Why Are My Custom Fields Not Showing Up Correctly?
I get this question more than any other. You've got critical data in a custom field, but when you pull it into Power BI, all you see is [Record] or [List]. Don't panic—this is completely normal.
Your data isn't gone; it's just nested inside that column. You just need to unpack it in the Power Query Editor.
- If you see
[Record]: Click the expand icon (it looks like two arrows pointing away from each other) in the column header. This will reveal the underlying properties, letting you pick the specific values you need, like.nameor.value. - If you see
[List]: This usually means you're dealing with a multi-select field. The "Expand to New Rows" option is your friend here. It will create a separate row for each selected value, which makes it possible to properly filter and analyze them.
What Is the Best Way to Calculate Cycle Time in Power BI?
Calculating accurate cycle and lead times is all about having access to the issue history. You absolutely need the timestamps for when an issue moved into and out of each status in your workflow.
The most reliable way to get this is by using a connector that's specifically designed to pull Jira's full issue history. This gives you a clean, pre-packaged table of all status transitions, ready to go. If you're hitting the API directly, you'll have to add changelog to the expand parameter in your query to get this data.
Once you have the history, you can build your calculations in Power BI using DAX. The DATEDIFF() function is your workhorse here. You’d create a measure that finds the timestamp for an issue entering "In Progress" and another for it entering "Done," then calculate the difference in days.
For teams that want to guarantee this data is clean from the very beginning, a tool like Harmonize Pro can be a huge help. Their app, Nesty for Jira, helps enforce structured workflows right inside Jira, making sure every status change is captured consistently. When your source data is that clean and reliable, building powerful Power BI dashboards for metrics like cycle time becomes much, much easier.
Leave a Reply